《领域驱动设计的原则与实践》读书笔记(一)
Chapter 1 什么是DDD:
1、介绍领域驱动设计思想体系
和传统开发方式比起来,领域驱动是一种新的软件架构设计,它主要用来解决传统开发中代码杂乱无章,任意拼贴等最终导致程序难以维护而诞生的。
它提出软件变得复杂和难以管理的主要原因是,领域复杂性和技术复杂性混合在了一起。
2、DDD如何管理复杂性
提炼问题重点、创建模型解决问题、使用公共语言建模协作、理解上下文关系。
DDD的侧重点:核心领域、协作、与领域专家探讨、复杂域模型的上下文理解。
3、DDD常见误区
DDD是框架、DDD是灵丹妙药
Chapter 2 提炼问题域:
1、知识提炼,领域知识的重要性
2、业务分析员,提炼知识是一个持续过程,每一次迭代,模型都会有所变化。
3、与领域专家一起获得见解
4、使用BDD专注于应用程序的行为
Chapter 3 专注于核心领域:
1、找出核心,支撑和通用域
2、提炼有助于降低问题空间的复杂性
3、并非一个系统的所有部分都被精心设计
Chapter 4 模型驱动设计:
1、Code First模型驱动设计
2、使用该领域的通用语言来在代码中描述,代码是表述模型的主要形式,需要使用通用语言来约束它。
3、要让团队里面领域中隐含的观念变得明确并赋予会组成共享通用语言的名称。
4、通用语言应该用于测试,类名称,和方法。
5、仅为核心领域应用模型驱动设计并创建UL才能带来变化,不要将这些实践应用到整个应用程序。
Chapter 5 领域模型实现模式:
1、领域层:是包含领域模型的代码区域,他将领域模型的复杂性和应用程序偶发的技术复杂性隔离开来,负责确保基础架构关注的是想管理事务和持久化这样的问题,而不会掺入业务问题并却不会让领域中已经有的规则变模糊。
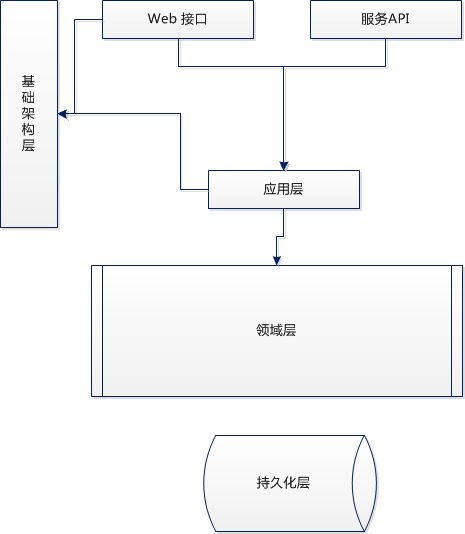

图1、表示领域模型代码仅构成整体代码库的一小部分
2、领域模型模式是基于没有数据库前提的,因此它可以演化并且以完全忽略持久化的方式来创建。
在设计领域模型时,不要从数据模型开始。相反要从代码模型开始(Code First),与数据驱动设计相反的模型驱动。仅当必须考虑模型持久化时,才能在设计上做出让步。模型内的领域对象成为普通老方C#对象(POCO)。这些类不再与基础架构问题有关并却完全忽略持久性。
3、事务脚本:事务脚本整个用例都是封装在单个方法中,如数据检索,持久化,事务管理,和业务逻辑。
事务脚本缺点:对于不知道面向对象的程序员来说是一种有帮助的模式,但是如果逻辑变得复杂,事务脚本会变得很难管理,事务脚本就会出现问题。
表模式:单个对象代表数据库中的一个表或视图,适合于数据库驱动设计(DB First),不适合DDD。这个模式适合于领域中由有界上下文隔离的更简单 部分以及简单数据形式来说,非常合适并且比领域模型模式更易于掌握。但是如果对象模型和数据库模型出现分歧,那么就需要朝着DDD模式的方向进行重构。
4、活动记录:类似于表模式,是一种流行的模式,每个业务对象都负责其自身的持久化一起相关的业务逻辑,类似于Repository<T>。
5、贫血领域模型:又称为反模式。违背了“只问不说”的原则,这个模式下领域服务会承担代码更具程序性风格的角色。贫血模型是DDD中一个良好开局。
Chapter 6 使用有界上下文维护领域模型的完整性:
1、大模型容易出错,系统扩展越多,模型越复杂
2、使用有界上下文和破除大模型
3、有界上下文拥有从展现层到领域逻辑层,再到持久化,甚至到数据存储功能的垂直切片。
并非所有的有界上下文都需共享相同的架构模式,如果有界上下文包含具有低逻辑复杂性的支撑或者通用域,那么可能会更倾向于使用CRUD的开发方式。
4、架构模式是在有界上下文的级别而非应用程序级别应用的,如果有界上下文没有复杂的逻辑,则可以使用简单的CRUD架构。
5、有界上下文中使用通用语言应该自主拥有从展现到领域逻辑,再到数据库和结构的完整代码堆栈。
Chapter 7 上下文映射:
1、上下文和上下文之间的耦合应该通过数据库来集成并共享一个模型。
2、如果业务跨越许多上下文,并越过领域的各个部分。这个时候理解有谁负责每个需要变更的上下文以及这一变化如何发生很重要。
3、防止损坏层会在另外一个上下文交互时为模型提供隔离。该层会通过提供一个上下文到另一个上下文的转译来确保不损害完整性。
4、如果有界上下文的集成成本太高且没有其他可用的非技术方法,那么应该遵循分道扬镳方式。
Chapter 8 应用程序架构:
1、DDD架构必须支持的一项内容是保持领域逻辑的隔离性。
2、分层架构
3、依赖倒置
领域层不依赖任何层,所有依赖关系都是向内的,它通过委托给领域层来组织对用例的处理。
领域对象需要持久化,怎么才能依赖倒置呢?通常使用在应用层定义一个让领域对象能够融合切持久的接口。这个接口从应用层的角度编写的。然后基础架构层会实现并且适配这些接口。
4、领域层、应用程序服务层、基础架构层
5、关于数据库,应该有界上线文有自己的数据库,而不是集成数据库,就像在领域模型内一样。这样避免了客户端代码很容易绕过有界上下文的保护以及领域对象状态的交互。
6、应用程序服务,定义和公开能力,业务用例写作。应用程序服务表示的是用例,不是CRUD
作为实现详情的领域层,领域服务方法可以揭示是否真的需要一个领域模型,如果发现所有业务都是CRUD,那么可以肯定,该领域缺乏所有真实的逻辑并且能通过使用事务脚本或者数据库封装模式来保持简化。
from:http://www.cnblogs.com/savorboard/p/5457324.html